EPIK
Precise and scalable evolutionary placement with informative k-mers
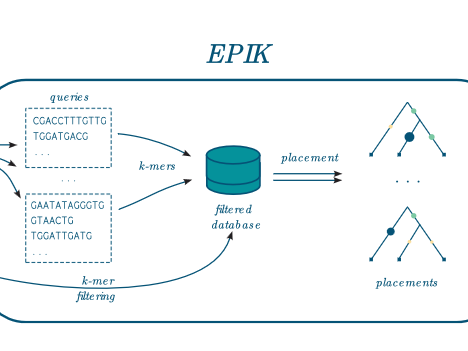
EPIK is a program dedicated to « Phylogenetic Placement » (PP) of metagenomic or metabarcoding reads on a reference tree.
It is similar in spirit and technically the successor of RAPPAS (Linard et al. 2020). EPIK achieves identical or slightly better accuracy than RAPPAS and outperforms it in speed and flexibility. In many aspects the documentation of RAPPAS remains valid.
EPIK takes as input a file containing database of phylo-k-mers built with IPK and a set of reads to place on the related phylogeny. It works for nucleotidic and amino-acid query sequences.
EPIK can filter the database to load only the most informative phylo-k-mers, which reduces the memory usage.
EPIK can also run in parallel.
Keywords
Phylogenetic placement, metabarcoding, taxonomic identification, NGS, software

The workflow combining IPK, to precompute the index, and then EPIK, to perform the placement of the reads.
Other tools

DExTER
Overview DExTER (Domain Exploration To Explain gene Regulation) is a bioinformatics tool designed to automatically identify genomic regions whose nucleotide composition correlates with gene expression levels. Unlike traditional approaches focusing on short transcription factor binding sites (6-12 bp), DExTER detects Long Regulatory Elements (LREs) that can span tens to hundreds of nucleotides. This makes it…

AQUAPONY
AquaPony: interactive visualization of phylogeographic scenarios AquaPony is a web application designed to explore and interpret evolutionary scenarios on annotated phylogenetic trees (for example, ancestral geographic states). It was built to make uncertainty in ancestral reconstructions easier to understand and communicate. Why AquaPony? In phylogeography, several scenarios can be nearly as plausible as the best…

TIDE
What is TIDE? TIDE is the orchestration platform behind ATGC online bioinformatics services. It provides a unified web interface and a public REST API to submit analyses, monitor jobs, and retrieve results across a growing catalog of phylogenetic and sequence-analysis tools. TIDE is a modernized redesign of WAVES, an older tool previously developped by ATGC…